🧮 任务提交和结果下载¶
如果你没有任何Linux基础,我们强烈建议你首先花费几十分钟乃至几个小时学习Linux基础知识,尤其是Linux文件系统导航操作。 此类操作非常简单, 教学材料内容也多。比如,你可以轻松找到大量视频教程。
我们将以运行Python代码为例进行讲解。
在开始此 任务提交和结果下载 教程前,请确保你已经登录到了GigaRiver。如果还没有完成登录,请查看 🔑 登录(Login) 。 同时,请下载下列此教程需要用到的文件到你的电脑:
其中,.py 文件是一个简单的python程序代码。我们将在此教程中运行此程序代码作为示范。而上述 .sh 文件是一个任务配置文件,
它包含了所有必要的任务信息(如任务的内容、所需的硬件资源、所需最大运行时间、输出结果的路径等等)。
我们将通过提交此文件至GigaRiver从而完成任务的提交。
同 🔑 登录(Login) 部分一样,我们这里使用MobaXterm作为工具特意为Windows用户提供教程。如果你已经是一位Linux/Mac用户, 你应该能迅速理解这个教程背后的原理/方法。
📤️ 文件上传¶
假如你需要GigaRiver为你运行此教程提供的样板代码 my_example_program.py,那么你首先需要把它上传到你在GigaRiver的目录。
上传方法非常简单。在已经成功完成登录到GigaRiver的MobaXterm终端(terminal)的左侧,你能够看到一个类似于Windows文件浏览器的可交互界面(文件导航界面),如下图。
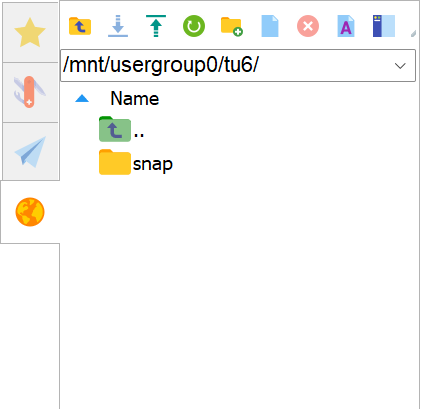
在你的文件导航界面中,图中的usergroup0应当被你所在的用户组(见 ➿ 用户组(User group))替代,tu6应该被你的用户名替代。注意,你可能看到比图中多得多的文件和文件夹。这是因为它同时显示了隐藏文件和文件夹。你可以点击此图中上方最右侧的按钮关闭显示隐藏文件和文件夹。¶
这个文件导航界面在其上端提供了数个交互功能按键。其中第三个为上传功能的按键(即上图顶部从左往右数的第三个,符号为向上的箭头)。点击此按键可以将本地
文件上传至GigaRiver你的当前文件目录(即此文件导航界面当下显示的目录)下。
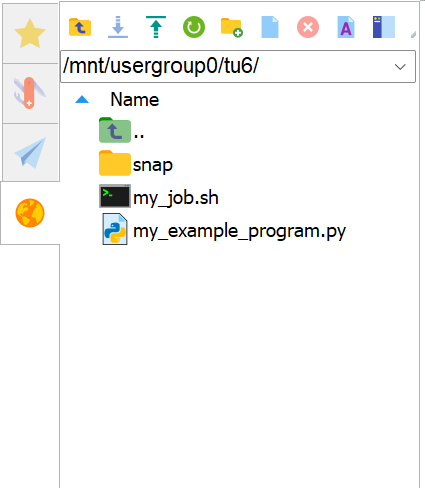
如果你成功使用这个功能将已经下载到本地的 my_example_program.py 和 my_job.sh 文件上传到GigaRiver,你将看到如下文件导航界面
⚾ 任务提交¶
在提交任务前,请确保你当前所处的目录包含了你刚上传的 my_example_program.py 和 my_job.sh 文件。
你可以通过 ls 命令查看当前目录所包含的文件信息。如:
$ ls
回车后你将在终端看到一个列表显示当前目录下的所有常规文件。如果你一直跟随此教程,那么你当前所处目录以及你上传文件的目录都应该是你的主目录(home)。
你可以使用 pwd 命令查看当前工作目录,即
$ pwd
默认情况下,终端应该返回
/mnt/usergroup0/yourusername
其中,usergroup0可能被替换成你所处的用户组,yourusername显示为你的GigaRiver用户名。如果你已经学习了基础Linux知识,
你应该已经知道如何使用 cd 命令导航至不同目录。那么你也可以尝试将上述文件上传至不同文件夹,并进行接下来的测试。
接下来,我们将介绍如何提交任务并且监视任务状态。
提交任务使用的命令是 sbatch 。提交的对象是 my_job.sh 文件,即一个简单的任务配置文件。现在,请你执行以下命令:
$ sbatch my_job.sh
如果任务提交成功,终端将返回一个作业号或任务号(JOBID)。比如
Submitted batch job 107
那么你提交的这个任务的任务号为107。接下来,你可以通过 squeue 命令查看任务信息,
$ squeue
你的终端将显示一个任务列表,其表头为
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
这个列表将展示所有的当前任务的信息;从左至右分别为
任务号(JOBID)
分区(PARTITION)
提交任务的用户名(USER)
状态(ST)
运行时间(TIME)
节点数目(NODES)
节点列表和状态原因(NODELIST(REASON))
你可以通过任务号(JOBID)来定位到你刚才提交的任务。
由于此教程任务只申请使用一个计算核心,
一般情况下,系统都具有足够资源运行执行此任务,因此你将在状态(ST)一栏看到R字样,即“运行中”。时间(TIME)一栏显示为运行的时间。此教程任务非常简单,
它将在约运行20秒以后完成运行。你可以反复执行 squeue 命令监视其状态。
如果任务较多,你也可以使用
$ squeue -u yourusername
来单独查看你提交的任务的状态(将上述命令中的yourusername替换成你的账号即可)。
一旦你发现你刚才提交的任务不再出现在任务列表中,说明它已经运行完成。此时,你再此运行 ls 命令,
你将在文件列表中发现两个新的文件,error.err 和 output.out。它们是此任务的输出文件,分别包含错误信息和输出信息。
如果你刷新终端左侧的文件导航界面(上传功能右侧的按键),你也将在文件导航界面看到 error.err 和 output.out 文件。
你可以双击它们中任意一个打开查看文件内容。第一次打开时,你的设备可能会询问你使用何种程序打开,你只需要选择你最常用的文本程序即可。
查看 error.err 文件你将发现此文件为空文件,即表示程序运行一切正常,未产生任何错误信息或警告信息。查看 output.out 你将看到如下输出信息:
Start....
1
2
3
4
5
6
7
8
9
10
Hello world. Hello, GigaRiver.
下面,我们将解释为什么你会看到这个此输出信息。
🛎️ 任务解释¶
如果你双击打开刚才提交的任务配置文件 my_job.sh,我们将看到它包含如下内容:
#!/bin/bash
#SBATCH --job-name=testjob
#SBATCH --partition=P0
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --mem=2G
#SBATCH --time=6-23:59:59
#SBATCH --output=output.out
#SBATCH --error=error.err
python3 my_example_program.py
其中第一行 #!/bin/bash 是指定Linux使用的脚本解释器,暂时无需了解,也不需要修改。接下来,我们能看到多行以 #SBATCH 开头的代码。
这些代码就是此任务的配置信息。每一行代表了一项配置,我们现在从上往下对每一条配置进行解释。
--job-name=testjob: 此任务的任务名为testjob。--partition=P0: 此任务将被分配至分区P0。你可以通过查看GigaRiver的硬件信息(⚙️ Hardware)或运行sinfo命令查看当前的分区情况。如果你不指定分区,任务将被分配至默认分区。--nodes=1: 此任务要求使用一个节点。如果你需要指定节点,你可以使用--nodelist选项,如添加一行#SBATCH --nodelist=n0,你的任务将只可能被提交至n0节点。--ntasks=1: 此任务需要启用1个线程。即说明它是一个单线程任务,没有并行运算需求。--mem=2G: 此任务需要的总内存为2G。--time=6-23:59:59: 此任务所需的最大时间。从任务开始计算时启动计时,如果超出了此时间任务仍然没有计算完成,GigaRiver将自动终止此任务。这里的时间格式是:天-时:分:秒。--output=output.out: 输出文件目录。程序的输出结果将被写入此文件。修改此选项可以自定义输出路径。你还可以使用%j来自动命名输出文件。如--output=output_%j.out,那么如果你的任务号是115,输出文件将被命名成output_115.out。--error=error.err: 错误信息文件目录。程序运行过程中产生的错误信息和警告信息将被写入此文件。一般而言,一旦产生错误信息,程序运行将立即终止。同--output选项, 你也可以使用%j来自动命名你的错误信息文件。如--error=error_%j.err
在这之后的代码将都将是发送给GigaRiver执行的代码。这里我们只有一行代码:
python3 my_example_program.py
也就是说,我们要求GigaRiver调用python3程序运行 my_example_program.py 文件。如果我们双击打开 my_example_program.py 文件,
我们将看到如下内容:
from time import sleep
print(f"Start....")
for i in range(10):
sleep(2) # 每次等待2秒再输出下一个数字,单纯为了延长次测试程序的运行时间
print(i+1)
print(f"Hello world. Hello, GigaRiver.")
可以看到,这是一个简单输出程序。开始时,程序将输出 Start....。
此后每隔两秒钟,它将输出一个递增整数。
并且在输出完10个数字(即20秒)后,它将输出 Hello world. Hello, GigaRiver. 作为结尾。这也就解释了之前查看 output.out 时看到的内容。
📥️ 结果下载¶
假如上述 output.out 文件是你需要下载到本地进行进一步分析的计算结果,
你可以通过MobaXterm文件导航界面顶端的第二个按钮(符号为一个向下的箭头)将GigaRiver里的文件下载到本地。
你只需要选择好需要下载的文件然后点击此下载按钮即可。另外,你也可以通过鼠标右击菜单里的下载选项下载所需的文件。(值得注意的是,使用类似的方法你也可以进行文件删除等操作。)
如果你的程序在执行过程中生成了其他的文件,如图片,数据文件等。根据你程序中设定的保存路径,你可以在GigaRiver中找到它们并使用相同方法下载到本地。
Important
但是,需要格外注意的一点是,GigaRiver不能进行图形界面交互。
也就是说,假如你的程序实时生成图片并显示的话(比如代码中使用了 matplotlib 制图并调用了 .show() 函数进行实时显示)系统将报错终止。
你应该将此部分设定成保存图片文件然后可以用上述方法下载查看。
同时,你应该尽可能降低文件保存的次数和保存文件的大小。因为这需要CPU向硬盘传输数据并让硬盘进行写入,这相对于运算而言要慢得多。
另外,所有的硬盘都挂载在主节点下,计算节点向硬盘写入文件时需要通过交换机进行数据传输,这将进一步降低写入速度。
所以,比方说你在一个时间迭代运算过程中的每一个时间步都保存计算结果或图像数据,那么这个生成结果或图片和硬盘写入数据的过程总耗时将非常可观。因此,在正式计算时应该考虑每隔一段时间进行一次保存、或只在特定时间点进行保存、又或者甚至只保存最终结果,从而减少与硬盘间交互的时间消耗。
换句话说就是,GigaRiver不适合用于程序的调试。你应该在本地完成你的程序调试。调试完成后,在进行大规模、长时间运算时你再使用GigaRiver。
另外,用户只有一定的储存空间(及其他硬件资源)限额,详情请查看 🤹 用户列表(User list)。
🎀 总结¶
简单而言,你只需要在本地编写好你的代码,将它们上传至GigaRiver,然后修改任务配置文件要求GigaRiver分配足够的资源,最后使用 sbatch 提交任务即可。
以Python为例,我们已经为GigaRiver安装好了常用的包, 并且已经配置好了DGMP组使用的 phyem (https://phyem.org/) 库, 你可以直接使用上述方法运行大负荷普通或phyem程序。
如果当前GigaRiver能够满足你提交的任务所需的资源,一般而言你的任务能够立即开始。
否则,你的任务将进入队列(任务状态 ST 将显示为 PD 即pending,意为等待中)。但是,在某些时候,GigaRiver会锁定一部分空闲计算资源。
即使这部分空闲计算资源能够满足你的需求,GigaRiver也不会将这部分计算资源用于你的任务。这可能是由于在你之前有用户提交了计算资源需求较大的任务。
由于这个大消耗任务在队列中的位置靠前,GigaRiver将首先尝试运行此任务。由于当前计算资源量不够,
为了积累足够的计算资源用于执行此任务,GigaRiver决定暂时锁定现有资源直至积累足够的资源后一次性分配给此靠前的任务。
总之,如果你想要你的任务快速执行,你需要检查当前队列情况和资源占用情况。 点击 ⚙️ Hardware 可查看GigaRiver的各计算节点的详细情况, 或者点击 🪵 Resource 查看各计算节点的计算资源简表。
Important
⚠️️ 重要: 请确保使用 sbatch (或者无任务配置文件时可直接通过 srun) 提交任务,
这样提交的任务将交由主(控制)节点(即master node)统一控制、分配、调度并监视计算节点(即computing nodes)进行计算。
由于主节点只需要执行控制、分配、调度、监视等简单任务,我们没有为主节点配置性能强力的硬件。如果你不使用 sbatch (或 srun),
而是直接执行比如下列命令
$ python3 my_program.py
这意味着你要求主节点为你调用 python3 程序运行代码,将严重占用主节点有限的算力,可能导致主节点反应迟钝,
甚至耗尽主节点内存而使得GigaRiver宕机。
⚠️️ 所以,再次强调,不要在GigaRiver里直接调用程序执行任何计算,永远选择 sbatch (或者 srun) 提交任务至任务管理系统。切记切记! ⚠️️
GigaRiver使用Slurm进行任务管理。已经介绍过的 sinfo, sbatch 和 squeue 等命令均为Slurm标准命令。
Slurm是一款强大的任务调度软件,在全世界范围内使用广泛,你可以轻易搜索到它的各种命令及使用方法。
我们将关于Slurm的一些常用命令总结在了 🚩 Slurm命令。
这里演示的内容仅仅是单线程任务,如果你需要执行并行任务,请参看 🖇️ 并行运算。
特别地,如果你使用phyem进行大规模并行运算,请参看 🅿️ phyem任务。